In the punch, we do not use logstash for high-performance logs parsing. Why is that? Mainly because logstash is nor easily scalable nor does it provide an end-to-end acknowledgment pattern. This is a serious lack because we cannot afford to lose logs whatever happens.
We thus selected an alternative technology (apache storm) to run our equivalent input/filter/output processors, and we designed a programming language (called punch) to deploy something similar than logstash filters in that engine.
This said, logstash is a great, simple and performant data processor, and we actually do use it in the punch, not to transform the data but instead to fetch external data using the various logstash input plugins.
This blog gives a few insights into the strengths and weaknesses of logstash, as well as some performance numbers.
News from Logstash
Let us start with some news from Logstash. On the performance side, Logstash is continuously progressing. First, it is now relying on a Java runtime. This improved the logstash performance significantly, have a look at this elastic blog.
On the scalability and resilience side, logstash is also getting better. They introduced internal queues. But the point is: their internal queue is only a partial answer. What you really need is to combine logstash with an external robust queuing system like Kafka, and to scale you must then add several logstash instances in a way to share the load. This is actually very clearly explained in this elastic recommendation blog.
A last important news: the elastic community is working on a Java API so that we can all provide java filters and input/output plugins. This will be way easier than embedding java calls inside a Ruby implementation. Hopefully, this will come soon. As soon as this is ready, we plan to provide a Punchlet filter implementation.
Punchlets are a punch sibling to logstash filters. Punchlets are small functions written using the punch language, with native supportfor groks, csv, dissect, kv and others operators, the ones made popular by Logstash.
Here is an example to parse apache logs. Using logstash you write something like this:
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
}
Using the punch you write a punchlet as follows :
{
if (!grok("%{COMBINEDAPACHELOG:[parsed]}").on([message])) {
raise("grok failed to parse apache log");
}
}
What this does is basically to transform an input apache log
Sep 23 08:54:30 host0 128.133.187.174 - frank [31/Dec/2012:01:00:00 +0100] "GET /images/KSC-94EC-412-small.gif HTTP/1.0" 200 26101 "http://www.example.com/start.html" "Mozilla/5.0 (iPad; U; CPU OS 4_3_5 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8L1 Safari/6533.18.5",
into a nicely parsed JSON document :
{
"parsed": {
"referrer": "http://www.example.com/start.html",
"request": "/images/KSC-94EC-412-small.gif",
"agent": "Mozilla/5.0 (iPad; U; CPU OS 4_3_5 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8L1 Safari/6533.18.5",
"auth": "frank",
"response": "200",
"ident": "-",
"bytes": "26101",
"clientip": "128.133.187.174",
"verb": "GET",
"httpversion": "1.0",
"timestamp": "31/Dec/2012:01:00:00 +0100"
}
}
Storm or Spark or … just a single application?
The beauty of logstash is its simplicity. It is a mere standalone java application. Just run it, no need to deploy a (spark/storm/flink) cluster. Of course, that simplicity is less attractive once you need to deploy many logstash instances on several servers. But for trying out, or even to go production on a small setup (a few thousand or tenth of thousands of logs per seconds), a simple logstash does the job.
The punch provides something exactly similar. Instead of deploying your pipeline to a real Storm cluster, you can also run it in a single standalone application. This is very handy because you can go production with small (punch)platform, one or three or a few more servers, without deploying a full storm cluster. Instead, the punch provides a lightweight process scheduler to let you safely run single-process pipelines. In a previous blog, we explained how simple this is to deploy a KafkaStream application. The same holds for any single-process pipeline apps.
To get an idea on how far you can go with a simple single-process processor, let us compare the performance of logstash versus the equivalent punch processor.
Performance Test
Here are the results of a very simple performance test. We will compare two similar pipelines:
- apache logs are received on a TCP socket
- a grok operator is applied to parse it
- the result is saved into a Kafka topic
Here are the two configuration files we used. First the punch pipeline. It is expressed using a spout and two bolts. These are storm concepts. A spout is an input connector, a bolt is a processing (i.e. filter) our output connector. Note in there the “./filter.punch” reference to a small punchlet file, the one that contains our punch function grok.
{
"spouts": [
{
"type": "syslog_spout",
"spout_settings": {
"listen": { "proto": "tcp", "host": "0.0.0.0", "port": 10001 }
},
"storm_settings": { "component": "input" }
}
],
"bolts": [
{
"type": "punch_bolt",
"bolt_settings": {
"punchlet" : [ "./filter.punch" ]
},
"storm_settings": {
"executors": 8,
"component": "filter",
"subscribe" : [ {"component" : "input"} ]
}
},
{
"type": "kafka_bolt",
"bolt_settings": {
"topic": "mytenant_digital_topology",
"brokers": "local",
"subscribe" : {"component" : "filter"}
},
"storm_settings": {
"component": "output",
"subscribe" : [ {"component" : "filter"} ]
}
}
]
}
Here is the similar logstash configuration: the grok pattern is defined here inline. (You can do that as well in the punch configuration file).
input {
tcp {
port => 10001
type => syslog
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
}
output {
stdout {}
kafka {
bootstrap_servers => "localhost:9092"
codec => json{}
topic_id => "mytenant_digital_logstash"
}
}
Note that these really look similar. The reason the punch pipeline is not as compact as the logstash one is because it defines an arbitrary graph. The graph is expressed using a publish/subscribe logic.
To conduct a fair comparison we used the same injectors, the one provided as part of the punchplatform, to generate 50000 apache logs per seconds. Both logstash and the punch processors were executed with the following parameters:
-Xms1024m -Xmx1024m -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly -Djava.awt.headless=true
Here is how you start logstash: bin/logstash -f logstash.conf and here is how you start the punch processor : punchplatform-topology.sh ./input_topology.json . Both are just as simple.
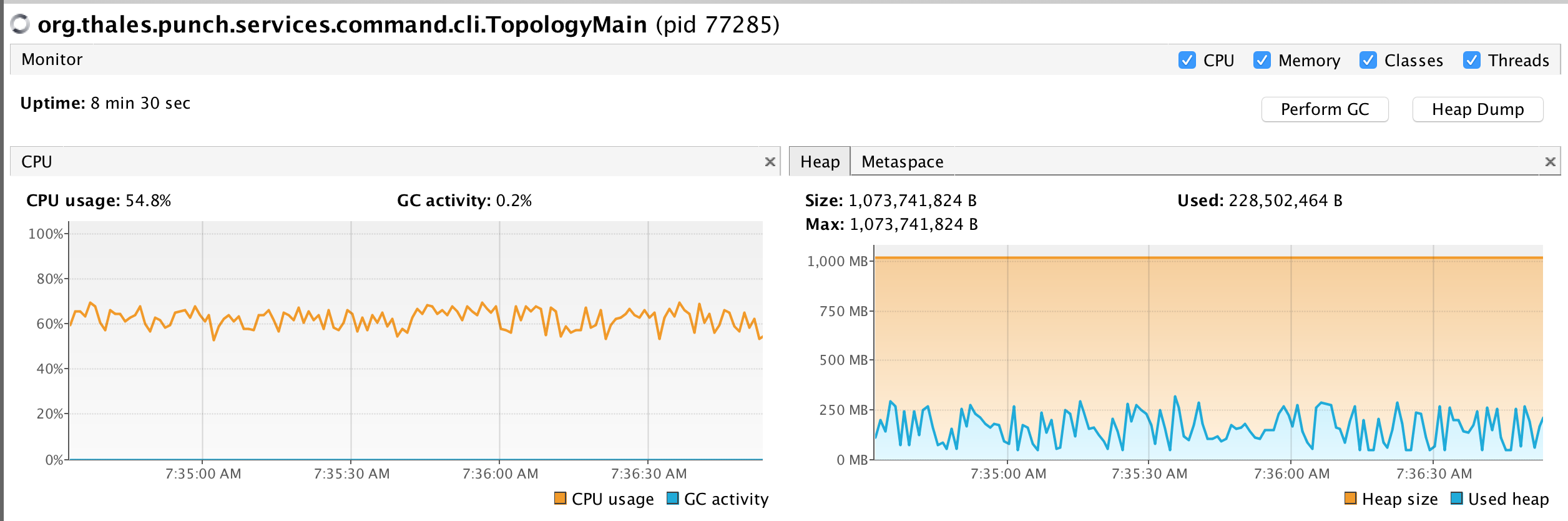
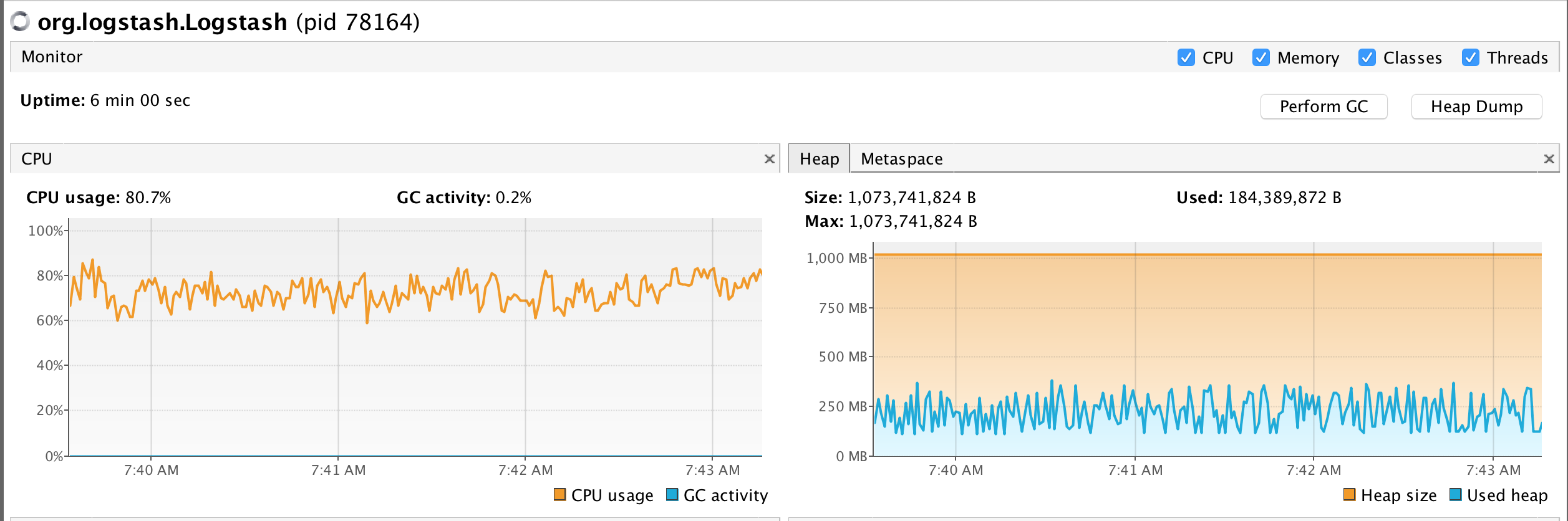
The test was conducted on a MacBook Pro (15-inch, 2017), 2,8 GHz Intel Core i7, 16 GB 2133 MHz LPDDR3. We these setups both logstash and the punch processors achieved 45 Keps. This was achieved with 8 threads running the filter part.
Here is a snapshot view of their respective CPU and memory occupation. As you can see, this is mostly similar, the punch processor takes slightly less CPU.
So What ?
What did we just illustrated?
Logstash and the punch both provide a simple and performant single-process pipeline model and application. Both are actually not equivalent, the punch model is based on the Storm DAG model, something like this:
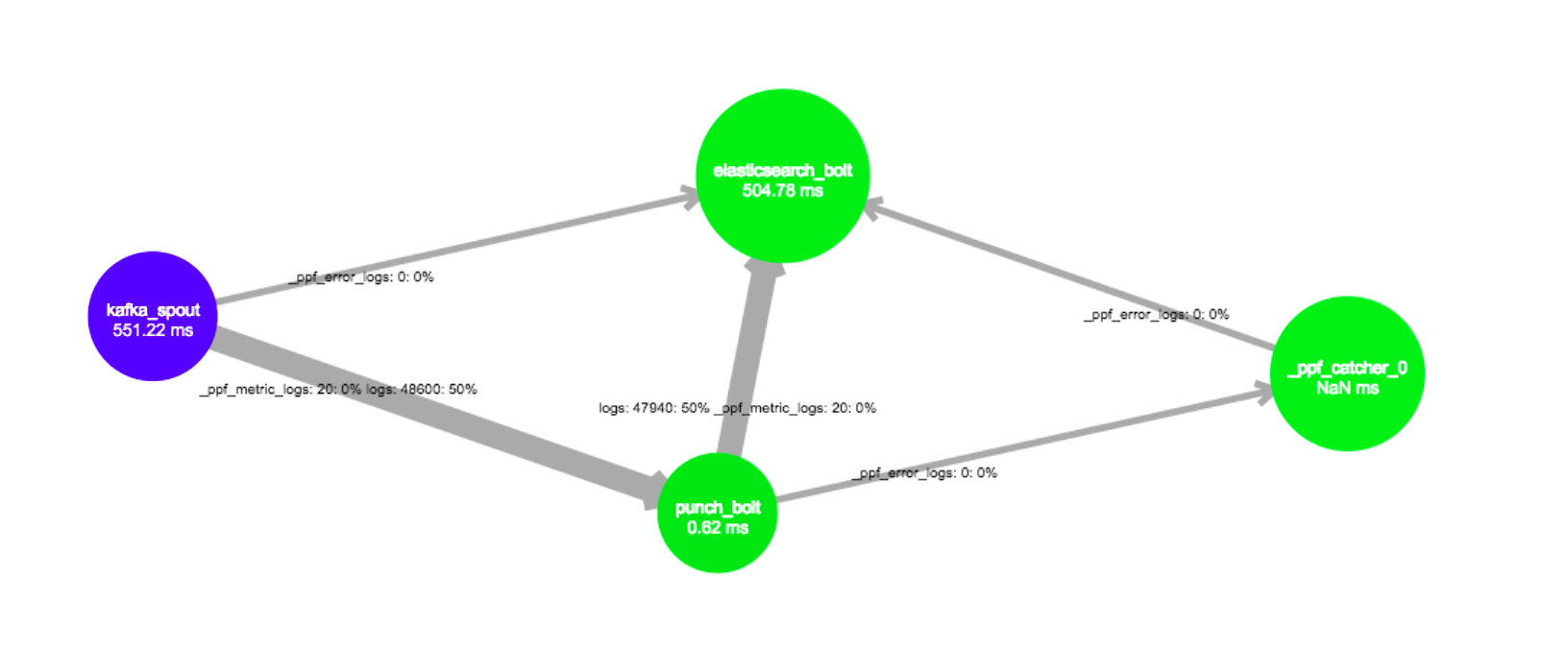
And this is way more powerful than the logstash pipeline. It lets you invent way more use cases than the logstash simple input-filter-output pipeline. You can generate alerts, route your data arbitrarily, and so on. More importantly, the punch pipeline is both scalable and resilient :
If you need more than a single process, use the (punch integrated) storm engine. And hop! your pipeline is distributed on 2, 5, or 10 processes automatically. No need to deploy and monitor several logstash. Resilient ? whatever you do, the data is acknowledged from each pipeline output connector back to the input connector. This is key so make sure you process each data at least one.
Note by the way that these acknowledgements come for free. There was no performance penalty.
The punch idea is that many use cases require a robust stream- (and batch-) processing engine. Logstash is not meant to cover these use cases. Say for example that you need multi-streams/window-based processing to correlate several streams of data in real time. Go KafkaStream !
If instead you need a machine learning (batch or stream) job? Go Spark ! And even better, do not code anything: use PML.
Does all that means that you should not use logstash? Quite contrary! If you can keep it simple, keep it simple. Just pay attention to logstash limitations, and envision the type of processing you will eventually need. Logstash is great.
Logstash is constantly improving and this is good news. True, its road to scalability and resiliency is somehow contradictory: instead of leveraging existing stream processing engines, they go their (hard) way by themselves. We preferred leveraging existing technologies, and we do that for more than three years with Storm, and more recently with Spark and KafkaStream. And we will continue to do so.
Next Ideas?
As explained, we already integrated logstash so as to easily pull data from various sources (http, jdbc, azure aws or google clouds). We have production systems where logstash instances are used to push the initial data to the punchplatform.
Now that they start designing the Java API, we also plan to develop a punchlet plugin so that our users will be able to run these compact punch function natively in logstash.
It is difficult to guess where logstash will go, but certainly further than we all expect.